§Reference I
- what happens when you type in a URL in browser
- What happens when you type an URL in the browser and press enter?
§Process
Attention: this is an extremely rough and oversimplified sketch, assuming the simplest possible HTTP request (no HTTPS, no HTTP2, no extras), simplest possible DNS, no proxies, single-stack IPv4, one HTTP request only, a simple HTTP server on the other end, and no problems in any step.
-
browser checks cache; if requested object is in cache and is fresh, skip to #9
- Browser cache. The browser maintains a repository of DNS records for a fixed duration for websites you have previously visited
-
browser asks OS for server’s IP address
-
OS cache. the browser would make a system call (i.e. gethostname on Windows) to your underlying computer OS
-
Router cache.
-
ISP cache. Your ISP maintains its’ own DNS server which includes a cache of DNS records.
-
-
OS makes a DNS lookup and replies the IP address to the browser
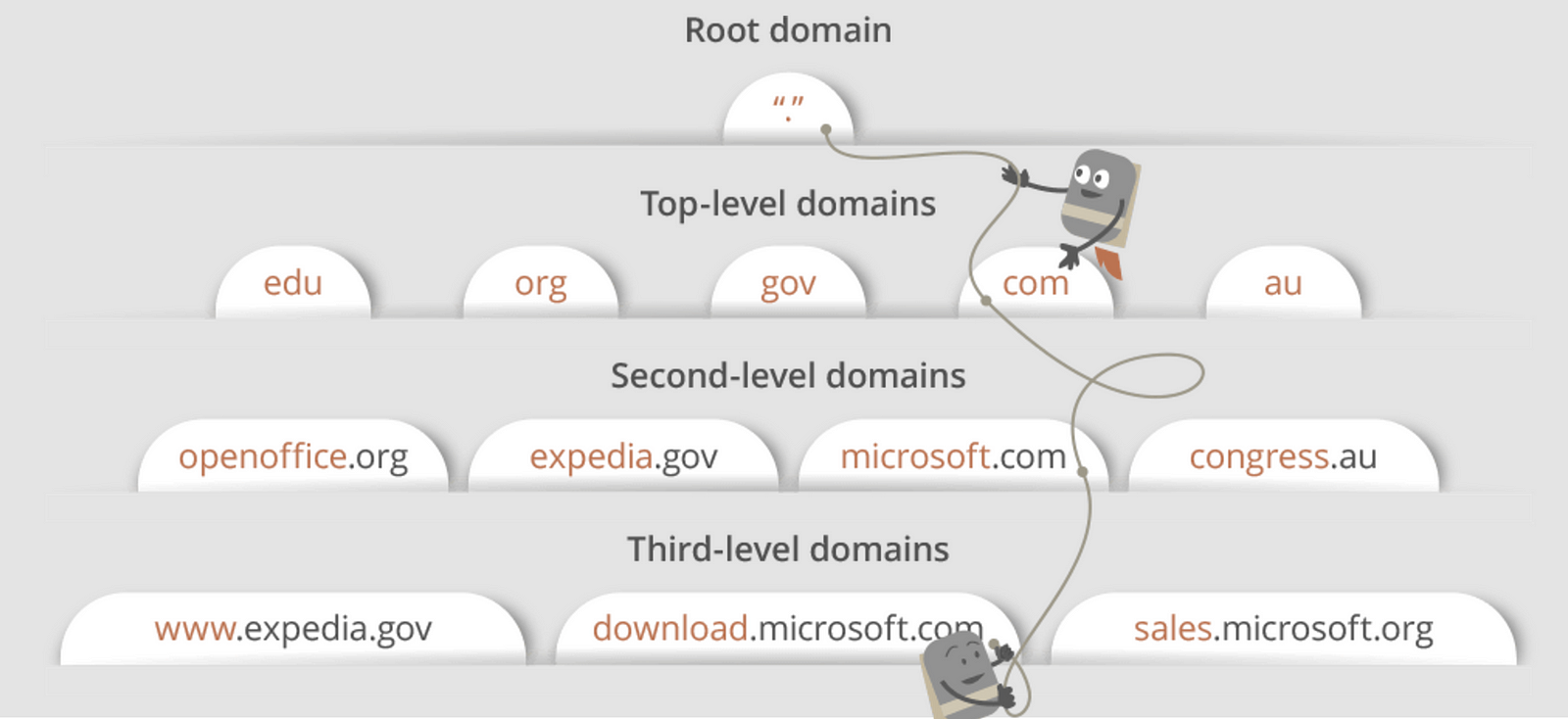
DNS(Domain Name System) is a database that maintains the name of the website (URL) and the particular IP address it links to. The main purpose of DNS is human-friendly navigation.
a recursive search since the search will continue repeatedly from DNS server to DNS server until it either finds the IP address we need or returns an error response saying it was unable to find it.
call the ISP’s DNS server a DNS recursor -> other DNS servers are called name servers
eg. DNS recursor -> root name server -> .com domain name server -> google.com name server, find the matching IP address
-
browser opens a TCP connection to server (this step is much more complex with HTTPS)
TCP/IP three-way handshake: the client and the server exchange SYN(synchronize) and ACK(acknowledge)
-
browser sends the HTTP request through TCP connection
GET/POST request, also contain additional information such as browser identification (User-Agent header), types of requests that it will accept (Acceptheader), and connection headers asking it to keep the TCP connection alive for additional requests.

-
browser receives HTTP response and may close the TCP connection, or reuse it for another request
The server response contains the web page you requested as well as the status code, compression type (Content-Encoding), how to cache the page (Cache-Control), any cookies to set, privacy information, etc.

-
browser checks if the response is a redirect or a conditional response (3xx result status codes), authorization request (401), error (4xx and 5xx), etc.; these are handled differently from normal responses (2xx)
-
if cacheable, response is stored in cache
-
browser decodes response (e.g. if it’s gzipped)
-
browser determines what to do with response (e.g. is it a HTML page, is it an image, is it a sound clip?)
-
browser renders response, or offers a download dialog for unrecognized types
First, it will render the bare bone HTML skeleton.
Then it will check the HTML tags and sends out GET requests for additional elements on the web page, such as images, CSS stylesheets, JavaScript files etc. These static files are cached by the browser so it doesn’t have to fetch them again the next time you visit the page.
At the end, you’ll see the page
§Reference II
§Details
-
从浏览器接收url到开启网络请求线程(这一部分可以展开浏览器的机制以及进程与线程之间的关系)
- 浏览器多进程:Browser进程(主控),第三方插件进程,GPU进程,浏览器渲染进程(内核,默认每个Tab页面一个进程)
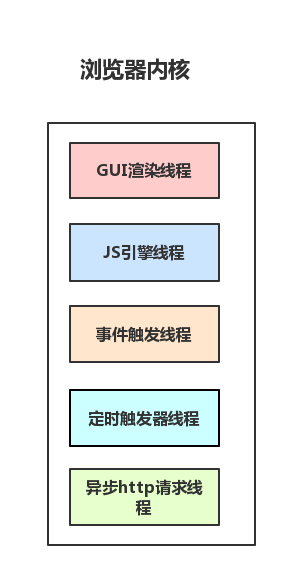
- 多线程的浏览器内核
- 解析URL:
protocol://host:port/path/query#fragment
-
开启网络线程到发出一个完整的http请求(这一部分涉及到dns查询,tcp/ip请求,五层因特网协议栈等知识)
-
DNS解析 -> IP Adress
-
tcp/ip请求构建:3次握手规则建立连接,断开连接时的四次挥手 -
五层因特网协议栈:
- 应用层(dns,http) DNS解析成IP并发送http请求
- 传输层(tcp,udp) 建立tcp连接(三次握手)
- 网络层(IP,ARP) IP寻址
- 数据链路层(PPP) 封装成帧
- 物理层(利用物理介质传输比特流) 物理传输(然后传输的时候通过双绞线,电磁波等各种介质)
OSI七层框架:
物理层、数据链路层、网络层、传输层、会话层、表示层、应用层- 表示层:主要处理两个通信系统中交换信息的表示方式,包括数据格式交换,数据加密与解密,数据压缩与终端类型转换等
- 会话层:它具体管理不同用户和进程之间的对话,如控制登陆和注销过程
-
-
从服务器接收到请求到对应后台接收到请求(这一部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
负载均衡:用户发起的请求都指向调度服务器(反向代理服务器,譬如安装了nginx控制负载均衡),然后调度服务器根据实际的调度算法,分配不同的请求给对应集群中的服务器执行,然后调度器等待实际服务器的HTTP响应,并将它反馈给用户
-
后台和前台的http交互(这一部分包括http头部、响应码、报文结构、cookie等知识,可以提下静态资源的cookie优化,以及编码解码,如gzip压缩等)

-
单独拎出来的缓存问题,http的缓存(这部分包括http缓存头部,etag,catch-control等)
强缓存(200 from cache)与协商缓存(304)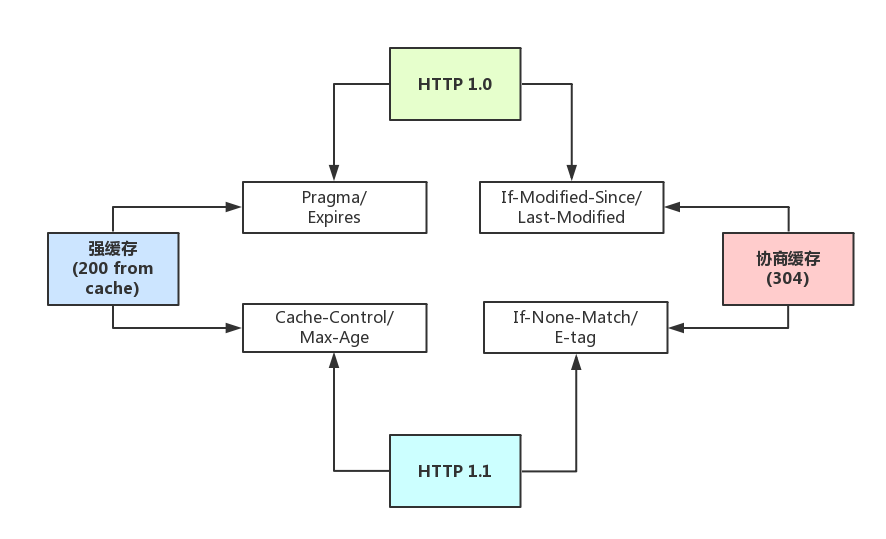
-
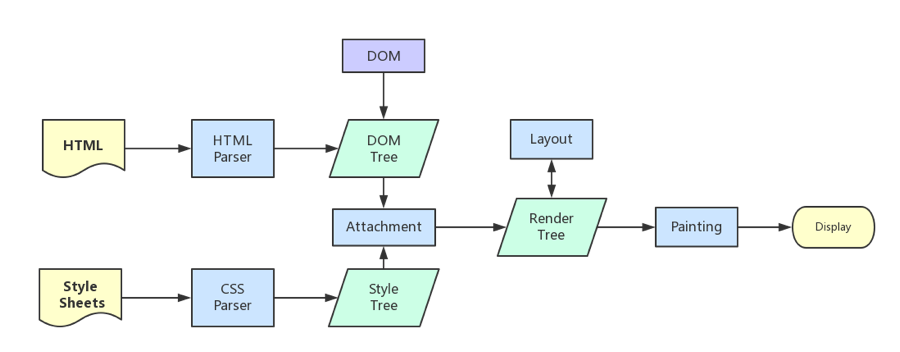
浏览器接收到http数据包后的解析流程(解析html-词法分析然后解析成dom树、解析css生成css规则树、合并成render树,然后layout、painting渲染、复合图层的合成、GPU绘制、外链资源的处理、loaded和domcontentloaded等)
-
解析HTML,构建DOM树
-
解析CSS,生成CSS规则树
-
合并DOM树和CSS规则,生成render树
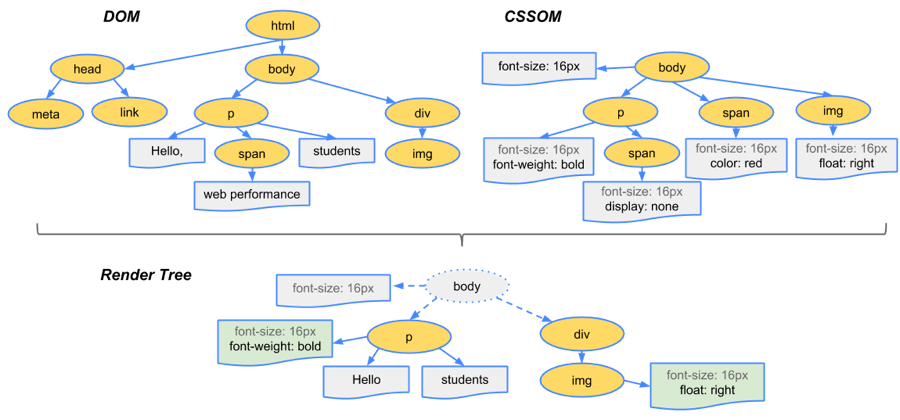
-
布局render树(Layout(reflow)/reflow),负责各元素尺寸、位置的计算
-
绘制render树(paint),绘制页面像素信息
-
浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上
-
-
CSS的可视化格式模型(元素的渲染规则)
-
包含块(Containing Block)
-
控制框(Controlling Box)
-
BFC(Block Formatting Context)
如何触发BFC?
- 根元素
float属性不为noneposition为absolute或fixeddisplay为inline-block,flex,inline-flex,table,table-cell,table-captionoverflow不为visible
-
IFC(Inline Formatting Context):行内元素自身如何显示以及在框内如何摆放的渲染规则
-
-
JS引擎解析过程(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
- 即时编译(
JIT-Just In Time compiler)- 读取代码,进行词法分析(Lexical analysis),然后将代码分解成词元(token)
- 对词元进行语法分析(parsing),然后将代码整理成语法树(syntax tree)
- 使用翻译器(translator),将代码转为字节码(bytecode)
- 使用字节码解释器(bytecode interpreter),将字节码转为机器码
- 即时编译(
-
JS的预处理阶段:Semicolon Insertion规则,分号补全,变量提升
-
JS的执行阶段
-
变量对象(
Variable object,VO) -
作用域链(
Scope chain) -
this:this的值只取决中进入上下文时的情况1
2
3
4
5
6
7
8
9
10
11
12
13
14var baz = 200;
var bar = {
baz: 100,
foo: function() {
console.log(this.baz);
}
};
var foo = bar.foo;
// 进入环境:global
foo(); // 200,严格模式中会报错,Cannot read property 'baz' of undefined
// 进入环境:global bar
bar.foo(); // 100
-
-
回收机制
- simple GC:
mark and sweep(标记清除),引用计数 - 分代回收(Generation GC)
- 多回收“临时对象”区(
young generation) - 少回收“持久对象”区(
tenured generation) - 减少每次需遍历的对象,从而减少每次GC的耗时
- 多回收“临时对象”区(
- simple GC:
- 其它(可以拓展不同的知识模块,如跨域,web安全,hybrid模式等等内容)