#Img
Containers with background images which zoom within their container on hover: Zooming Background Images
Or you can test it online: css background image zoom with transition
Maybe you just want to clip it to a complex shape, here is CSS clip-path maker
#Font
Use Google Fonts API to add fonts to your web pages.
JavaScript console in Sublime Text
- Tools -> Build System -> New Build System…
1 | { |
-
Save as JavaScript.sublime-build
-
Choose Automatic/JavaScript, run *.js
1 | var fName = function(fVal) {}; |
LeetCode | SQL
[TOC]
§Problems
§Basic
1 | SELECT DISTINCT Email |
183. Customers Who Never Order
1 | SELECT c.Name AS Customers |
184. Department Highest Salary
1 | SELECT d.Name AS Department, e.Name AS Employee, e.Salary |
1 | DELETE p1 |
1 | SELECT w1.Id |
§JOIN
1 | SELECT p.FirstName, P.LastName, A.City, A.Sate |
181. Employees Earning More Than Their Managers
1 | SELECT a.Name AS Employee |
§Rank
1 | SELECT Max(Salary) AS SecondHighestSalary |
1 | CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT |
1 | # Write your MySQL query statement below |
1 | SELECT DISTINCT l1.Num as ConsecutiveNums |
1 | -- using user-defined variables |
185. Department Top Three Salaries
1 | SELECT d.Name AS Department, e.Name AS Employee, e.Salary AS Salary |
§Basic knowledge
§Links
§SELECT - extracts data from a database
1 | SELECT column1, column2, ... |
1 | # SQL Server / MS Access Syntax: |
1 | MIN(), MAX(), COUNT(), AVG(), SUM() |
§UPDATE - updates data in a database
1 | UPDATE table_name |
§DELETE - deletes data from a database
1 | DELETE FROM table_name |
§INSERT INTO - inserts new data into a database
1 | # If only insert in specified columns, others = null |
§ALIASE - give a table, or a column in a table, a temporary name
1 | 1. |
§JOIN - combine rows from two or more tables, based on a related column between them
1 | SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate |
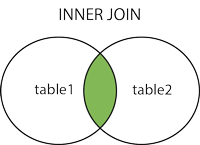
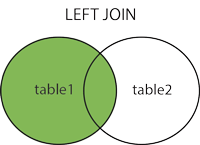
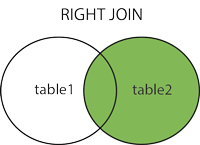
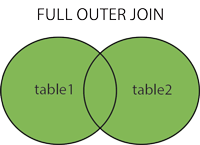
-GROUP BY statement - used with aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the result-set by one or more columns.
1 | SELECT COUNT(CustomerID), Country |
§Operators
1 | UNION, UNION ALL with duplicate values |
§Comments
1 | -- Single line |
§DATABASE
- CREATE DATABASE - creates a new database
- DROP DATABASE - drop an existing SQL database
- ALTER DATABASE - modifies a database
§TABLE
- CREATE TABLE - creates a new table
1 | CREATE TABLE table_name ( |
- DROP TABLE - deletes a table
- ALTER TABLE - modifies a table
1 | ALTER TABLE table_name |
- CREATE INDEX - creates an index (search key)
- DROP INDEX - deletes an index
- …
Leetcode | Maximum Length of Repeated Subarray
718. Maximum Length of Repeated Subarray
Given two integer arrays A and B, return the maximum length of an subarray that appears in both arrays.
Example 1:
1 | Input: |
Note:
- 1<= len(A), len(B) <= 1000
- 0 <= A[i], B[i] < 100
! subarray, not subsequence
- I. DP,
- Similar to LCS
- Time Complexity: O($L_A$x $L_B$)
- Space Complexity: O($L_A$x $L_B$)
1 | //c++ |
- II. Optimization
- DP
- Time Complexity: O($L_A$x $L_B$)
- Space Complexity: O($L_A$)
1 | //c++ |
- III. Optimization 2
- DP
- Time Complexity: O($L_A$x $L_B$)
- Space Complexity: O(1)
since dp[i][j] only depends on dp[i-1][j-1], we only need to keep it and traverse the matrix diagonally.
1 | //Java |
- IV. HashMap
1 | //c++ |
相关题目
- 115. Distinct Subsequences
count the number of distinct subsequences of S which equals T
DP, O(n) space
1 | class Solution { |
- 最大连续子序列和,乘积,最长递增子串,最长公共子串,子序列等问题(动态规划等)
- Some programs are online.
MDS(multidimensional scaling)Map
MDS(multidimensional scaling)多维尺度分析
模式识别之 MDS Multidimensional Scaling 多维尺度法 分析及Matlab实现
A Nonlinear Mapping for Data Structure Analysis
A Nonlinear Mapping for Data Structure Analysis PPT
A Nonlinear Mapping for Data Structure Analysis wiki
Sammon Projection
Sammon Mapping
百度面试总结
首先说一下侥幸心理,当时收到百度通知去大厦面试的时候心里活动如下(懵^n
想着居然过了笔试,也是real可怕,还是很开心的去了。
申的是Web前端研发实习岗
其实是有点心虚的,大一大二算是知识的巅峰期,目前就是以抛物线的形式下降。收到面试通知以后强行找了一些题目,临时抱了一下大腿,倒没有完全写过。
很多已经处于知道有这个,似乎是因为什么,具体怎么描述既不大清了。。。
果然今天面试的时候就跪了
大幸是一面和二面对我比较和善,有幸面了三面。
一面二面都比较基础,一面主考HTMK/CSS,还有用js写一个函数(用到了递归的思想,还是比较简单的),二面的时候被问了关于从一维数组构造树的问题,一开始答的一般,没有考虑输入的乱序,例如pid可能不存在,后来就说也是类似递归呗,往上生成。
其实一面二面都是很简单的问题,还有就是因为太久没用js写这类实际问题的函数,连数组用push都忘了。显而易见,也被一面和二面都提了说我js基础不够的问题。
但到了三面已经明显看到力不从心了。同样问了一下比较基础的内容,依旧有点答不清楚(其实还是那几个inner、block、inner-block,display/visibility,事件绑定,ajax,get/post等等。其实是知道的,但是当时自己都觉得答的混乱。(顺便一说,这几个其实一二三面有重叠的问道,但是中间间隔的时候我没有好好回顾。。。二面面完12:30左右,给时间吃午餐,然后13:00一面,所以也就没吃。。。(后来发现我算是进度快的,大部分人都是一面结束再1点开始。
再回归正文。三面这里就比较惨了,给了时间让我现场google然后说区别,一开始限制用英文,后来说都可以(不过中英文倒还好,最多看的速度差异。。。),还有一些现场code test,他应该也看出来我基础的问题了,说写伪代码也行。
问我用过什么框架,我也就最多一个bootstrap,也没用过node.js(果然还是深入不够,后期就得自我反思了。。。
总之我后面自己都心虚了。。。然后他打算从别的地方看看我的优点,例如算法什么的。。。就问我搜索字符串什么方法,我的想法非常naive,肯定有问题。他后来给了用KPM、BP(这个时候我还是懵
写到这里应该能意识到我妥妥地跪了,最后他就让我问一个问题,我就问我距离百度还需要做多大努力。。
他说了一些(综合思想是很多。。
后来再想问,就被打断说只有一个问题。。
一脸尴尬的我
不过三面的时候还有基础面一定只有我了QAQ
感觉面试官还是很帅气很有思想的,当时感觉好年轻一定很厉害所以就很开心地做过去了。。。果然被虐的很厉害。
在等hr过来收表格的时候可能也有点尴尬,稍微问了点别的,比如学校什么的,然后又说现在还是不够之类的,说大学毕业也不能忘记算法(其实并无毕业。。。),问了面试官是本科毕业工作么,然后了解到他是社招。
然后也了解到,其实还会问关于前端项目的注意点啦,比如说性能啊安全多屏幕适配等等(应该看我比较弱渣所以没问到这个。。。(然而我内心os是这个还稍微能扯点似乎,毕竟还是写过项目,只是好久没写了。。。另外还有一个问题就是学校里接触的项目要求不是很高,自己也没太花功夫。。
所以结果这样还是意料之中的,自嘲为北京一日游也是真心的。
所以开心的和小伙伴约了饭,和当时一起面试的几个学长学姐留了微信,有缘再见啦
果然还是有很多路要走,继续加油咯我,还有你们~
啊,最后说一句,当时好想要三面面试官的邮箱或者微信之类的联系方式,没敢。。。无比后悔ing
算法-图论-Kruskal
23.2-1 对于同一个输入图,Kruskal算法返回的最小生成树可以不同。这种不同来源于对边进行排序时,对权重相同的边进行的不同处理。证明:对于图G的每棵最小生成树T,存在一种办法来对G的边进行排序,使得Kruskal算法所返回的最小生成树就是T。
直接想法就是再加一个在输入时边的顺序(即相同权重看哪条边存储的在前面就选哪条)。。。这能怎么证明><
顺便po上为了解决这个问题顺便复习和思考的内容(对,思考XD
§相关
- Kruskal算法是每次选择权重最小的边加入森林,它的本质是贪心算法。
- 如果该图所有的边均不相同,那么我们可以证明最小生成树唯一
- 如果各边权值唯一,从最小生成树开始,每次加一条边i并在新生成的环上删除最大的一条边j(满足权值$e_i$ < $e_j$),这时会得到一棵新的生成树,如果我们加入的那条边满足 $e_j$- $e_i$最小,那么得到的就是第二小的生成树。从这个第二小的生成树开始,进行同样的操作可以得到第三小的生成树。这个迭代过程中树的权值是一直递增的,所以不可能出现相同权值的多棵最小生成树。
- 对于给定的图而言,因为最小生成树的权值和是确定的,所以最小生成树不唯一当且仅当最小生成树的形状不唯一
- 可证明最小生成树T与任意生成树T’,对边进行排序$w_1$ <= $w_2$ <= … <= $w_n$ , $w_1’$ <= $w_2’$ <= … <= $w_n’$ 有 $w_i’$ <= $w_i’$
- 如果i时第一个有 $w_i’$ < $w_i$,即有$w_n$ >= $w_{n-1}$ >= … >=$w_i$ > $w_i’$ >= $w_{i-1}’$ >= … >= $w_1’$。
- 所以如果我们选择{$w_1’$ … $w_i’$}中某边加入T,要么产生与{$w_1$ … $w_{i-1}$}产生环,要么就是{$w_1$ … $w_{i-1}$}中某边。
- 所以在选择边 $e_1$ … $e_{i-1}$ 后有n-i+1个联通分量,再加入边 $e_1’$ … $e_i’$ 后仍为n-i个联通分量,但事实上,因为来自于生成树T’,所以边 $e_1’$ … $e_i’$ 能够有n-i个联通分量
- 所以矛盾。
§另,最小生成树唯一性判定
- 对图中每条边,扫描其他边,如果存在相同权值的边,则对该边进行标记;
- 然后用Kruskal(或者Prim)算法求MST(最小生成树);
- 求得MST后,如果该MST中未包含做了标记的边,即可判定MST唯一;如果包含作了标记的边,则依次去掉这些边再求MST,如果求得的MST权值和原MST权值相同,即可判定MST不唯一。
§转
某版23.1-8 把一个连通无向图的生成树边按权值递增排序,称排好序的边权列表为有序边权列表,则任意两棵最小生成树的有序边权列表是相同的。(算法导论)
证: 设最小生成树有n条边,任意两棵最小生成树分别称为A, B, 如果e是一条边,用w(e)表示该边的权值。
A的边按权值递增排序后为a1, a2,……an w(a1)≤w(a2)≤……w(an)
B的边按权值递增排序后为b1, b2,……bn w(b1)≤w(b2)≤……w(bn)
设i是两个边列表中,第一次出现不同边的位置,ai≠bi
不妨设w(ai)≥w(bi)
情形1 如果树A中包含边bi,则一定有j>i使得 bi=aj ,事实上,这时有 w(bi)=w(aj)≥w(ai) ≥w(bi) 故 w(bi)=w(aj)=w(ai),在树A的边列表中交换边ai和 aj的位置并不会影响树A的边权有序列表,两棵树在第i个位置的边变成同一条边。
情形2 树A中并不包含边bi,则把bi加到树A上,形成一个圈,由于A是最小生成树,这个圈里任意一条边的权值都不大于w(bi) ,另外,这个圈里存在边aj不在树B中。因此,有w(aj)≤w(bi),且j>i (因为aj不在B中)。于是,有w(bi)≤w(ai)≤w(aj)≤w(bi),因此 w(ai)= w(aj) = w(bi)。那么在树A中把aj换成bi仍然保持它是一棵最小生成树,并不会影响树A的边权有序列表,并且转换成情形1。
如何基于场景设计产品-笔记(20160418)
###场景的定义是什么
- “场景”最早出现在电影、电视剧的制作过程中,而在互联网产品中,指用户需求的“环境”。
- 用户场景 -> 用户需求,场景不同,需求不同
- 场景包括用户自身,外部环境:如网络等人、事的不同流程与状态
- 场景下的需求即用户使用的出发点 -> 设计产品迭代、维护等
§为什么要基于场景设计产品
-
§产品已成为场景下的体验
- 与传统产品的工具性需求不同,互联网,以人为重心,讲究人与互联网的结合。可能成本低廉,但能满足人的更深层次的需求。
- 满足情感上的、个性化的需求。而这些是与产品分不开的,例如和朋友聚餐、情侣约会和自己吃饭是不一样的
- 例子:微信红包(“伪”需求)+春节场景 -> 场景点燃情感,情感点燃需求
- =>产品融入了场景 = 基本功能+附加值 => 打动用户
-
§移动终端加速了产品场景化
- 之前的PC等,对位置等是有一定限制的,而移动终端则有更多的场景,有更多的产品需求,催生了产品相应的价值。
- 特殊场景,如定位类:百度地图,O2O百度糯米
-
§O2O产品扩展了产品的边界
- 线上和线下的联系 -> 扩展了产品边界:比如百度糯米,现在有了团购产品,线上团购,线下消费。从用户获得消息,线下消费
- 从团队化、标准化到定制化、个性化:从套餐 -> 打折券
- 新的场景出现,如定电影票
§具体例子:百度手机卫士
-
§来去电飘窗,前置化场景的功能,接打电话时手机出现小飘窗出现这个号码的当前信息
- 因为用户在接打电话之前了解是否是诈骗电话等,所以必须在当前环境下实现。
- 需求用户不会告诉你 -> PM提炼成可以在产品上实现的需求,例如:骚扰电话多 = 电话的场景下,让用户提前知道电话的信息
-
§悬浮窗:手机桌面上的小圆点,点击可加速
- 为什么是悬浮窗,为什么是加速
- 使用手机不知道什么时候会变慢变卡,所以手机卡慢贯穿整个使用的场景,而悬浮窗有这个特质,安卓手机可设置从而在所有界面都能看到 => 所以只有悬浮窗可以满足需求,也只有手机卡慢可以放在上面
- -> 场景和需求的结合
-
§手机加速功能分支下的小功能
- 有哪些场景下,用户会有额外典型的手机加速的需求?如玩游戏,因为需要性能 -> 所以设置成,启动游戏时自动加速
-
§为什么基于场景 ->因为产品已经成为特定场景下的体验
- 思考用户需求,思考在这个用户需求下的场景,现在的环境是什么,然后再把场景细分 -> 可能有比较能打动人心的新的点
§同学提问:
-
如何去发现“伪场景”:场景和需求结合在一起,我们可以说 如果是伪场景,那一定也是伪需求;所以其实本质是如何发现伪需求。那么我觉得可以有几点参考:不关注用户说什么而多关注用户做什么;实际去调研,去体会;关心用户最终的目标
-
老师你好,如何确定一个功能是强需求高频率的呢,靠用户调研?:用户调研当然是最简单也最直接的方式;但是在有些情况下,用户调研也会说谎,如果我们没有能力进行调研,我们就可以通过拆解需求,拆解功能,找到功能的本质,进而去发现功能是否是高频的;比如抢红包,拆解以后是不是还有小额转账的功能,这就是一个高频需求
-
我想问下产品的特性是全面好还是单点极限表达好?:核心需求单点极限,初期产品单点极限,但是也不是绝对;比如o2o 永远是越多越好
-
场景细分一般可以从那些层面和纬度去进行细分:可以从场景中涉及到的所有人和事开始,然后每个人、每个事 是否有不同的状态
-
请问老师,在产品初期没有用户的时候怎么做用户体验 用户场景的设置?: 我觉得还是需求的拆解,需求拆解到极致,一定是可以找到切入点的。把这个切入点和已经存在的场景来寻找互通
-
一个产品在多个场景下应用时不同需求冲突该如何解决?: 一个产品在多个场景下应用时不同需求冲突该如何解决?
-
做竞品分析的时候,如何快速分析出一个产品的定位?:还是看功能
-
如果说产品朝个性化定制化方向发展,是不是意味着我们做出来的产品可能会比较小众化:个性化是手段,不是目的;小众产品也可以很优秀的呀
-
刚才您提到微信的抢红包功能,当时它不是用户可能会想得到的或者可能需要的需求,它是微信上有了才慢慢被接受,您认为是一位的做用户需求调查重要呢?还是脑洞大开一下更重要一点? : 调查一定是有的,脑洞大开也保不准,但是根本还是其创造者抓住了发红包这种情感的宣泄点,有理有据,才能引爆
-
老师您好,请问在产品推出后,如何去做到更好的维护这个产品,以及如果因为时间等某些因素面临场景的改变怎么办:你指的维护产品可能就是产品的迭代和生长吧,产品也像一个孩子,要明白在不同的阶段 让它做不同的事情吧
-
如何筛选场景呢?不可能满足所有场景:按产品核心需求排优先级,看看场景是否解决了或者契合了核心需求
-
一个产品的核心功能的满足会不会因为场景的满足而产生偏移呢?:需求和场景分不开,如果核心功能被满足,那就是核心场景被满足,然后引发的是额外高阶的需求,那就是不同的场景了
-
说用户需求就会谈到用户体验,如何理解这两者:大概就是手动挡和自动挡的区别
-
老师能说明一些产品迭代的不同时期,考虑的不同需求吗?并且如何考虑的:不是产品迭代左右需求,是需求催生了产品迭代
-
请问老师,随着产品功能的不断扩展,某些功能可能会与其他产品的某种功能发生叠加,这个时候我们是选择保留这种功能还是放弃以保留产品的独特性?:思考为什么会出现重叠?思考去掉或者保留的利弊
-
请问老师,是应该是让场景下的功能无限接近用户需求,还是应该让用户能无限适应场景下的功能: 很好的问题,找平衡,因为需求有时候是伪需求,或者说不完美的需求,你要有自己的判断
-
请问老师,针对刚才被提到的同质化问题,如果已知自主设计的产品会被模仿的情况下应采取何种设计产品的策略呢,采取模仿别人的策略有何不妥:不要忘了产品的初衷,是解决用户需求,而不是应对别人的模仿
-
老师我想请问:那您觉得如果设计一款产品是很全面好呢,比如一个APP包涵了衣食住行的各种O2O服务、也包含了手机安全等功能;还是纯粹地分别设计安全app、团购app、酒店住宿app比较好?因为现在确实手机app越来越纷繁复杂,用户难以选择,而且审美疲劳或是选择疲劳也会导致用户选择乏力,那么您认为将来的趋势是:针对越来越细分的场景和用户需求设计越来越小众的app呢,还是推出一款返璞归真的app,包含尽可能多的功能和场景需求。哪一种可能更成功?: 嗯 我觉得这个问题很好;我的回答是,这不是选择的问题,而是能力的问题;现在没有什么企业可以把一个app做到包含你的所有功能而又不显得臃肿,繁杂,无所适从;试想,如果真的出现了一个真正意义的人工智能app,只需要你一句话就能满足所有需求,何乐而不为呢? 先让大家把每个点做到极致,再考虑综合的问题吧
-
请问如何判断一个产品是否成功了呢?装机量?用户正面评价?营收额?受到资本青睐?:求仁得仁喽
-
在产品功能愈发齐全、场景需求愈发得到满足的背景下,以场景为思路来改进产品功能是否容易陷入瓶颈?是否以后对产品的改进会更加趋向于个性化定制?: 是可能会陷入瓶颈,不过还是那句话 个性化是手段 不是目的,更多还是要发现新场景新需求
-
用户调研如何发现潜在的需求:多关心用户真正去做什么
-
互联网产品在现在市场下的发展趋势:发展肯定会越来越好,互联网化是大趋势了,会影响生活的方方面面
-
现在很多互联网公司所推出的应用都提到了上述所提功能,那么在竞争激烈、同质化严重的市场环境下,企业要如何保证自己的产品能在某个特定场景下最受用户的青睐:可以从产品、运营各个方面来回答。如果说特定场景下,那一定是产品的体验做到极致
-
悬浮窗一般在电脑上使用,复制到手机上,如何解决用户在手机屏幕这么小的空间上因为使用悬浮窗而带来的不适感(屏幕被霸占感觉)?:可以从感情上找一些共鸣,比如设计的趣味性、个性化、娱乐性。如果实在不喜欢,还可以隐藏呀
-
请问有什么工具或原则来高效设计用户场景吗?:设计用户场景我觉得这个说法可能不合适,用户场景需要我们去深入的理解,需要我们设计的 是产品的形态 所以用你的大脑去设计用户场景吧
-
百度手机卫士,360手机卫士和手机管家的产品定位有区别吗?:对用户的核心需求上没有区别,但是结合产品在公司的战略意义,会有战略上的区别
-
说用户需求就会谈到用户体验,如何理解这两者:大概就是手动挡和自动挡的区别
-
学生团队如何做到从0到1?寻找怎样的平台?怎样的契机?:我觉得去做就很好了,哪怕是从0到0以后,还能剩下的东西 就是100
-
是应该是让场景下的功能无限接近用户需求,还是应该让用户能无限适应场景下的功能:很好的问题,找平衡,因为需求有时候是伪需求,或者说不完美的需求,你要有自己的判断
-
请问百度手机卫士APP首页上的“家人防护”是基于什么样的场景,它为什么能有这么高的优先级?:这个就属于成熟型产品的一个方向性尝试吧。
出现一个新功能前三个月只能全是市场实验,新功能的出现可以改变生活态度,但是要被市场接收还需要好的营销!和用户习惯的养成
§产品的路远没有人人都是产品经理这句话说的这么简单。多体会,多思考,多实践。
[整理/转载]Github+HEXO (Mac)(二)
§配置评论
- Hexo默认集成Disqus提供第三方评论系统
- 国内建议多说
- 登录后在首页选择 “我要安装”。
- 创建站点,填写站点相关信息。 多说域名处填写自己命名的short_name 例如博主就根据提示顺手填了ZoeyeoZ。。。
- 创建站点完成后编辑站点配置文件_config.yml文件
- 新增 duoshuo_shortname 字段,值设置成上一步中的值。
duoshuo_shortname: ZoeyeoZ- 此外声明这类配置与主体有关,博主主题[NexT]
- 如果采用其他第三方评论系统,通用代码详见多说网站
使用多说的话,Thread Key一定不要改变,Thread Key相当于是识别码;如果你更新了Hexo或者重装了vps,文章的Thread Key改变了的话,那么恭喜你,评论全部没有了。。。
§百度统计
- 登录百度统计, 定位到站点的代码获取页面
- 复制 hm.js? 后面那串统计脚本 id,如:
hm.src = "//hm.baidu.com/hm.js?xxxxxx";- 编辑站点配置文件,新增字段 baidu_analytics 字段,值设置成你的百度统计脚本 id
§阅读次数统计(LeanCloud)
-
详细内容参照为NexT主题添加文章阅读量统计功能
-
NexT主题目前已经合并这个Feature,因此如果你使用的是NexT主题,可以直接使用不用修改主题模版
-
修改NexT主题模版
-
详见原文
-
修改_config.yml文件
在blog/themes/next -
添加lean-analytics.swig文件,
在blog/themes/next/layout/_scripts -
修改post.swig文件
在blog/themes/next/layout/_macro -
修改layout.swig文件
在blog/themes/next/layout -
修改zh-Hans.yml文件
-
注册LeanCloud(需验证邮箱)
-
配置LeanCloud
登录帐号,配置后拿到AppID及AppKey,用于文章阅读量统计的功能。-
创建应用,用于博客的访问统计的数据操作
- 左上角账号,打开控制台
- 点击创建应用
- 新建的应用名称Test(可修改)
- 点击新创建的应用名进入参数配置页
- 点击左侧右上角的齿轮图标,创建Class。新建表来保存数据
为了保证我们前面对NexT主题的修改兼容,此处的新建Class名字必须为Counter
- 选择Counter,点击顶部设置,切换到Test应用操作界面
- 选择左侧的应用Key选项,得到创建应用的AppID以及AppKey
- 复制AppID以及AppKey并在NexT主题的_config.yml文件中我们相应的位置填入即可
- 注意,NexT用户需要修改false为true
leancloud_visitors: enable: true - 重新生成部署Hexo博客,应该就可以正常使用文章阅读量统计的功能了。需要特别说明的是:记录文章访问量的唯一标识符是文章的发布日期以及文章的标题,因此请确保这两个数值组合的唯一性,如果你更改了这两个数值,会造成文章阅读数值的清零重计。
-
-
后台管理
- 初始的文章统计量显示为0,这时对应应用的Counter表中并没有相应的记录。当博客文章在配置好阅读量统计服务之后第一次打开时,便会自动向服务器发送数据来创建一条数据,该数据会被记录在对应的应用的Counter表中。
- 我们可以修改其中的time字段的数值来达到修改某一篇文章的访问量的目的(博客文章访问量快递提升人气的装逼利器)。双击具体的数值,修改之后回车即可保存。
- url字段被当作唯一ID来使用,因此如果你不知道带来的后果的话请不要修改。
- title字段显示的是博客文章的标题,用于后台管理的时候区分文章之用,没有什么实际作用。
- 其他字段皆为自动生成,具体作用请查阅LeanCloud官方文档,如果你不知道有什么作用请不要随意修改。
-
Web安全
由于AppID以及AppKey是暴露在外的,为确保只用于自己博客,建议开启Web安全选项,这样就只能通过自己的域名才有权访问后台的数据- 选择应用的设置的安全中心选项卡
- 在Web 安全域名中填入我们自己的博客域名,来确保数据调用的安全
- 如果填写错误可能导致博客文章访问量显示不正常,打开浏览器调试模式,发现Web安全域名填写错误,导致服务器拒绝了数据交互的请求,请修改或者放弃。。。
§Swiftype 搜索
- 使用 Swiftype 之前需要前往 Swiftype 配置一个搜索引擎。 而后编辑 站点配置文件, 新增 swiftype_key 字段,值为你的 swiftype 搜索引擎的 key。 详细的配置请参考: 第三方服务 - Swiftype
- 进入Swiftype,根据提示操作
- 注意,修改值在 /blog/themes/next/_config.yml 内
# Swiftype Search Key swiftype_key: xxxxxxxxx - 复制Install Swiftype On Your Website内的
_st('install','XXXXXXXXX','2.0.0');
- 注意,修改值在 /blog/themes/next/_config.yml 内
§JiaThis
- 编辑 站点配置文件, 找到字段 jiathis
jiathis: enable: true
§ERROR
- 如发生类似错误
- ERROR Process failed: layout/_scripts/.DS_Store
- ERROR Process failed: layout/.DS_Store 等
- 进入主题里面layout和_partial目录下相应目录下,使用删除命令:
rm -rf .DS_Store
[整理/转载]Github+HEXO (Mac)
参考
§配置环境
安装Node.js -> 生成静态页面的
安装Git -> 把本地的hexo内容提交至github(Xcode自带Git)
申请GitHub
§安装Hexo
sudo npm install-g hexo
输入管理员密码(Mac登录密码)即开始安装
(sudo:linux系统管理指令 -g:全局安装)
注意坑一:Hexo官网上的安装命令是 npm install -g hexo-cli,安装时不要忘记前面加上sudo,否则会因为权限问题报错。
-
终端cd到一个你选定的目录,执行hexo init命令
hexo init blog//blog是建立的文件夹名称 -
cd blog,npm install//安装npm -
hexo s//开启hexo服务器 -
本地浏览器,http://localhost:4000

§配置Github
- 关联Github
- 检查SSH keys是否存在Github
ls -al ~/.ssh//检查SSH keys是否存在.- 如果有文件github_rsa.pub或github_dsa.pub,则直接将SSH key添加到Github中,否则进入下一步生成SSH key。
- 生成新的ssh key
ssh-keygen -t rsa -C "your_email@example.com"//生成public/private rsa key pair- 注意将your_email@example.com换成你自己注册Github的邮箱地址。
- 默认会在相应路径下(~/.ssh/github_rsa.pub)生成github_rsa和github_rsa.pub两个文件。
- 将ssh key添加到Github中
- Find前往文件夹~/.ssh/github_rsa.pub打开github_rsa.pub文件
- 进入Github -> Settings -> SSH and GPG keys -New SSH key ->
- Title内容任意,key为github_rsa.pub内容
- 创建仓库
- 登录你的Github帐号,新建仓库,名为用户名.github.io固定写法
- 本地的blog文件夹下内容为:
- _config.yml
db.json
node_modules
package.json
scaffolds
source
themes
- _config.yml
- 终端cd到blog文件夹下,vim打开_config.yml
vim _config.yml - 在文件最后deplo修改如下
- deploy:
type: git
repository: https://github.com/yourID/yourID.github.io.git
branch: master - yourID请换成自己的用户名。
- hexo 3.1.1版本后type:值为git。
- deploy:

注意坑二:在配置所有的_config.yml文件时(包括theme中的),在所有的冒号:后边都要加一个空格,否则执行hexo命令会报错。
博主本人的报错为FATAL bad indentation of a mapping entry at line 72, column 15:
请确认您使用空格进行缩进(Soft tab),并确认冒号后有一个空格。
- 在blog文件夹目录下执行生成静态页面命令
- ``hexo generate`` 或者 ``hexo g``
- 此时若出现如下报错:
ERROR Local hexo not found in ~/blog
ERROR Try runing: 'npm install hexo --save'
若无报错,自行忽略此步骤。
博主本人的报错为``ERROR Deployer not found: git``
均执行命令:
``npm install hexo --save``
- 再执行配置``hexo deploy`` 或者 ``hexo d``
- 比较奇怪的是之后居然要求我输入用户名和密码(私以为SSH已经搞定
注意坑三:若执行命令hexo deploy仍然报错:无法连接git,则执行如下命令来安装hexo-deployer-git:
npm install hexo-deployer-git --save
再次执行hexo generate和hexo deploy命令
- 此时,浏览器中打开网址http://yourID.github.io(将gonghonglou换成你的用户名)能看到和打开http://localhost:4000时一样的页面。
- 发布文章
- 终端cd到blog文件夹下
-hexo new "postName"//新建文章,位于目录/blog/source/_posts下
- 编辑文章
- 终端cd到blog文件夹下
-hexo generate//生成静态页面
-hexo deploy//将文章部署到Github
§安装theme
- 更多官方主题请戳Hexo官网主题页。这里以hexo-theme-next为例
- 终端cd到 blog 目录
git clone https://github.com/iissnan/hexo-theme-next themes/next- 将blog目录下_config.yml里theme的名称landscape修改为next
- 终端cd到blog目录下执行如下命令(每次部署文章的步骤)
hexo clean//清除缓存文件 (db.json) 和已生成的静态文件 (public)hexo g//生成缓存和静态文件hexo d//重新部署到服务器- 附:NexT 使用文档
- 更改theme内容,修改 blog/_config.yml 文件和 blog/themes/next/_config.yml 文件中对应的属性名称即可。
- 不要忘记冒号:后加空格。
§绑定个人域名
- 还未绑定,有兴趣的同学请访问原文。